Useless Art: An adventure in self-hosting open AI models using Elixir
Generative AI! Generative AI! Generative AI!
Seems to be top-of-mind for nearly every (tech) person at this point. While most deployments in the wild boil down to calling an API from one of the big players, I was curious to see what it would take to build application around self-hosted open-source open-weight AI models. There’s been an absolute proliferation of open models under permissive licenses thanks to the likes of Meta, Mistral AI, Stability AI, and others. And the gap between open and closed models seems to be closing at a rapid pace.
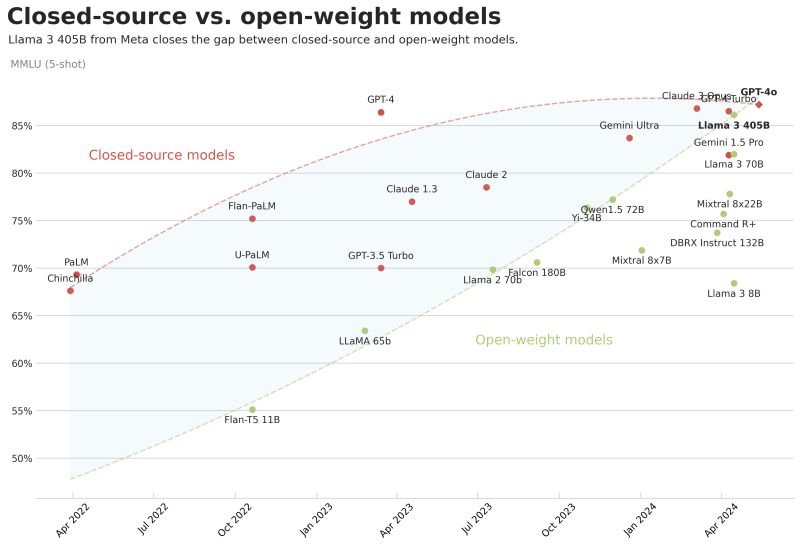
This is where my new project Useless Art comes in!
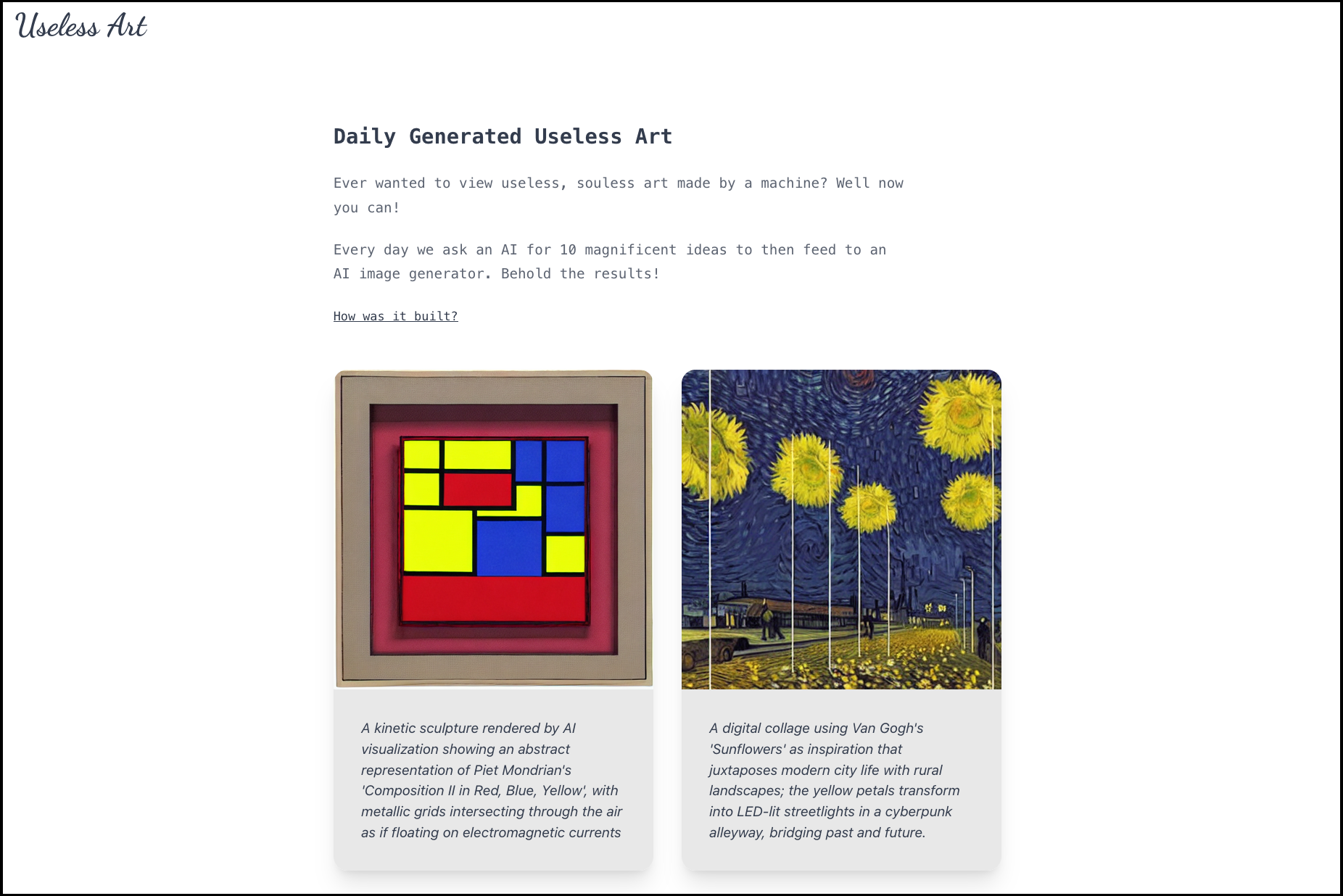
The premise behind Useless Art is pretty straightforward. Every day, we prompt a large language model to provide a list of interesting art ideas, then pass those ideas over to a diffusion model that then generates the images. The images are then displayed on the page. While simple in concept, this allows me to experiment with hosting two types of generative models, LLMs and Diffusion models.
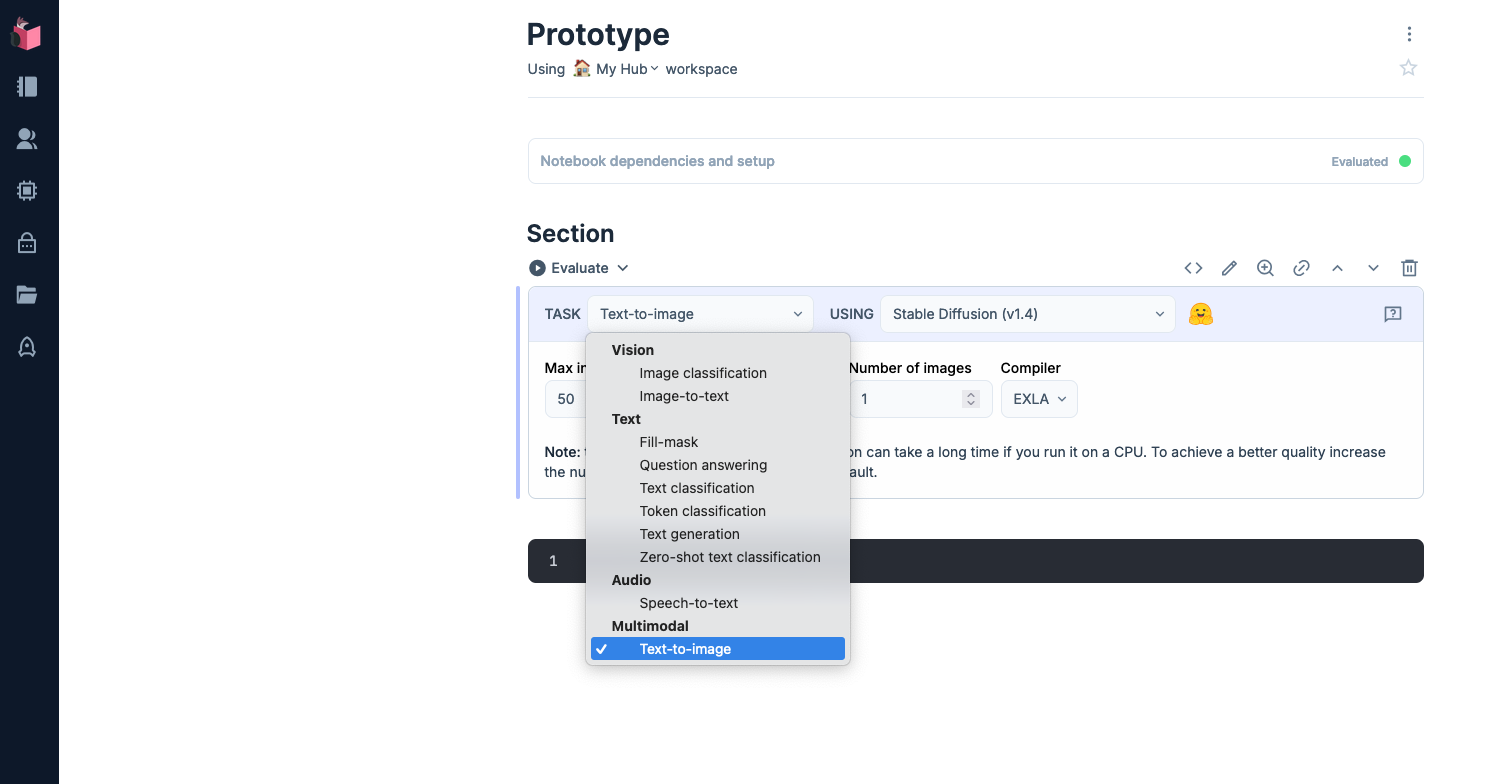
The first step was to decide which models I wanted to use and build a prototype. I used the handy “smart” cell feature of Livebook which has integrations for different ML tasks to test the capabilities of Stable Diffusion 1.4.
I already had in mind the Phi3 model from Microsoft as it performs nearly as well as models with twice the number of parameters due to higher quality training data. I experimented with having the model generate prompts for the Stable Diffusion model using Ollama. After verifying that Phi3 was indeed able to readily generate interesting prompts and that the SD model was capable of producing images that match the captions, I had all the pieces in place.
I went with Elixir and Phoenix for building the web app as
- Elixir is my favorite programming language
- Phoenix is the best
- I’ve been wanting to try out Bumblebee
Since I was just going to be sticking with a CPU for inference, I knew I wouldn’t be able to generate these images on the fly so I decided to schedule image generation nightly using Oban. Elixir Nx, which Bumblebee sits on top of, uses XLA for its backend. EXLA, which packages XLA, was compiled for an old Linux machine I had handy with an i7 6700 and 32 GB of RAM. I’m assuming it’s configured to use the CPU’s SIMD extensions. Get the SD model to work with Bumblebee was super easy. There’s a high-level interface with a fully working example in the docs.
repository_id = "CompVis/stable-diffusion-v1-4"
{:ok, tokenizer} = Bumblebee.load_tokenizer({:hf, "openai/clip-vit-large-patch14"})
{:ok, clip} = Bumblebee.load_model({:hf, repository_id, subdir: "text_encoder"})
{:ok, unet} = Bumblebee.load_model({:hf, repository_id, subdir: "unet"})
{:ok, vae} = Bumblebee.load_model({:hf, repository_id, subdir: "vae"}, architecture: :decoder)
{:ok, scheduler} = Bumblebee.load_scheduler({:hf, repository_id, subdir: "scheduler"})
{:ok, featurizer} = Bumblebee.load_featurizer({:hf, repository_id, subdir: "feature_extractor"})
{:ok, safety_checker} = Bumblebee.load_model({:hf, repository_id, subdir: "safety_checker"})
serving =
Bumblebee.Diffusion.StableDiffusion.text_to_image(clip, unet, vae, tokenizer, scheduler,
num_steps: 20,
num_images_per_prompt: 2,
safety_checker: safety_checker,
safety_checker_featurizer: featurizer,
compile: [batch_size: 1, sequence_length: 60],
defn_options: [compiler: EXLA]
)
prompt = "numbat in forest, detailed, digital art"
Nx.Serving.run(serving, prompt)
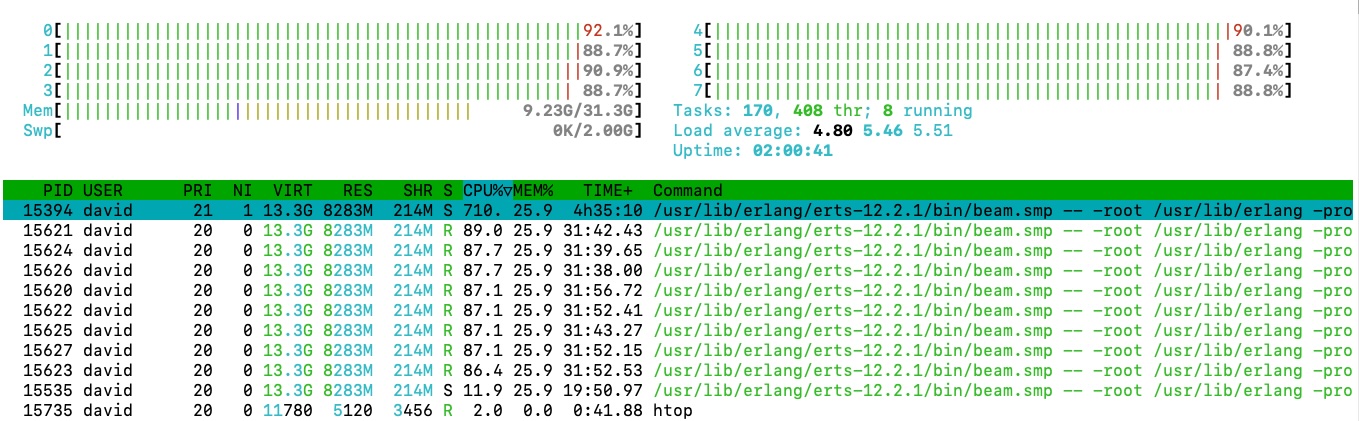
Testing this on my machine shows maximal utilization of the CPU, with all cores at almost 100% utilization.
I did try running the Phi3 model with Bumblebee, however in comparison with Ollama, the quality of the output was much lower and performance was quite poor, so I stuck with leveraging Ollama’s API. However, in the future, this could be moved to Bumblebee as things continue to improve.
Putting this all together, we have a Phoenix web app that uses Phi3 and Stable Diffusion to regularly generate art. It took less than a day to put the entire app together as the Elixir ML tooling is quite excellent. Obviously this nowhere near as straightforward as calling an API from an AI company which might even be more economical in certain cases given infrastructure costs but there’s a ton of great tooling out there to make hosting open models very feasible.